News
[2025.01] We are pleased to inform you that our paper has been accepted for presentation at ICRA 2025!
Method
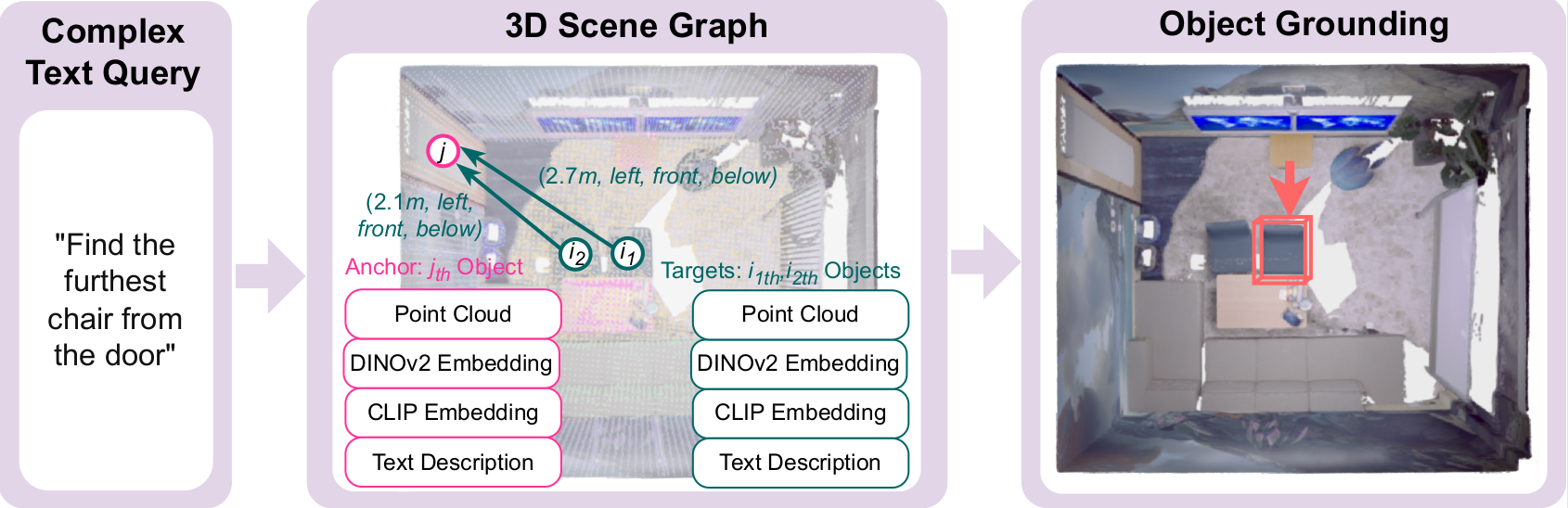
Proposed BBQ approach leverages foundation models for high-performance construction of an object-centric class-agnostic 3D map of a static indoor environment from a sequence of RGB-D frames with known camera poses and calibration. To perform scene understanding, we represent environment as a set of nodes with spatial relations. Utilizing a designed deductive scene reasoning algorithm, our method enable efficient natural language interaction with a scene-aware large language model.
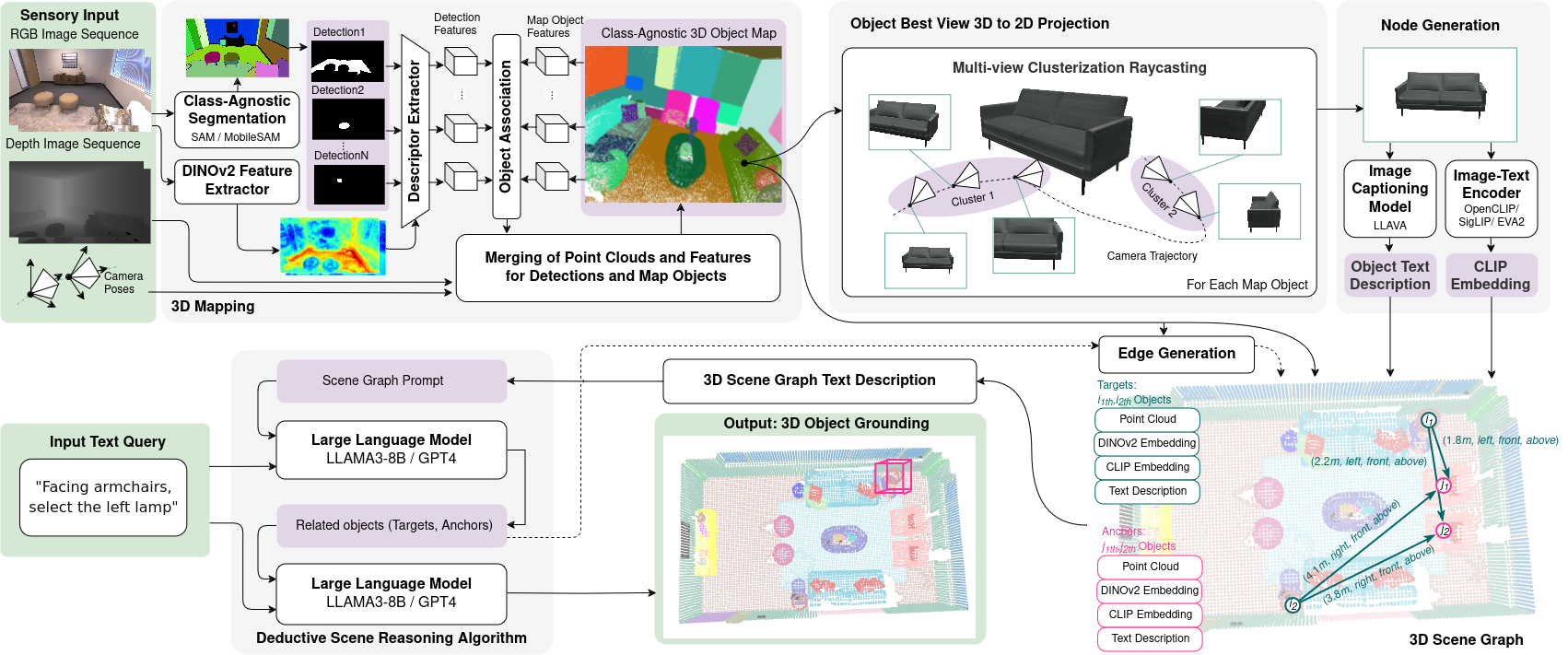
An object-centric class-agnostic 3D map is iteratively constructed from a sequence of RGB-D camera frames and their poses by associating 2D MobileSAMv2 mask proposals with 3D objects with deep DINOv2 visual features and spatial constraints (Sec. III-A). To visually represent objects after building the map, we select the best view based on the largest projected mask from L cluster centroids that represent areas of object observations (Sec. III-B). We leverage LLaVA [15] to describe object visual properties (Sec. III-C). With the node’s text descriptions, spatial locations, metric and semantic edges (Sec. III-D) we utilize LLM in our deductive reasoning algorithm (Sec. III-E) to perform a 3D object grounding task.
Results
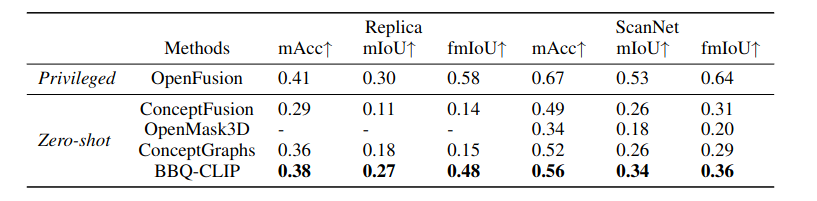
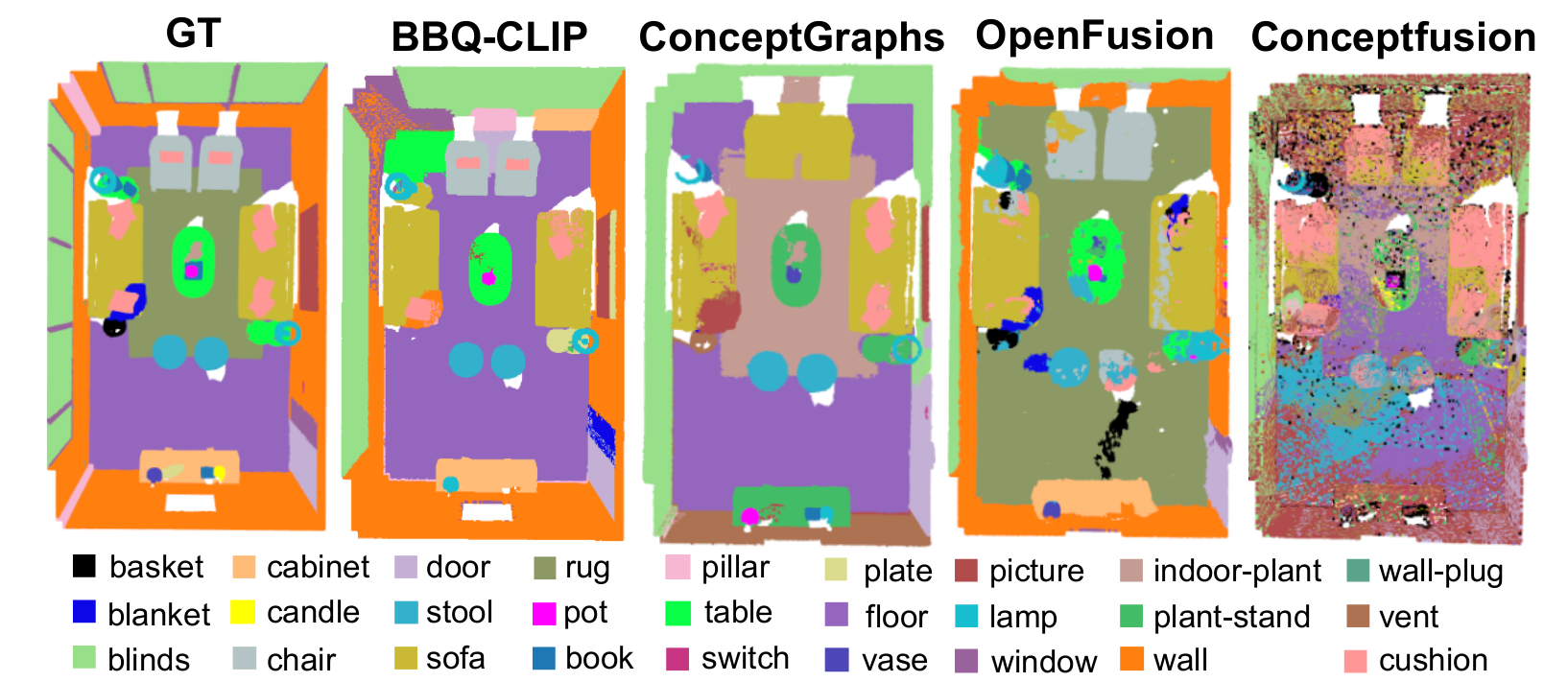
3D open-vocabulary semantic segmentation
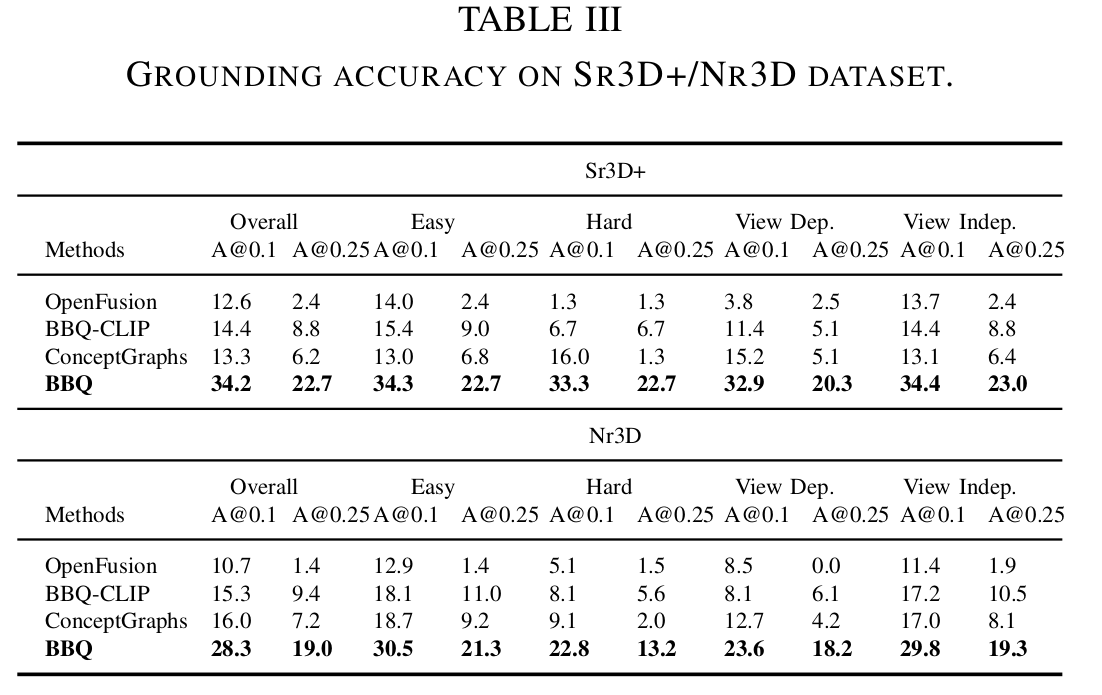
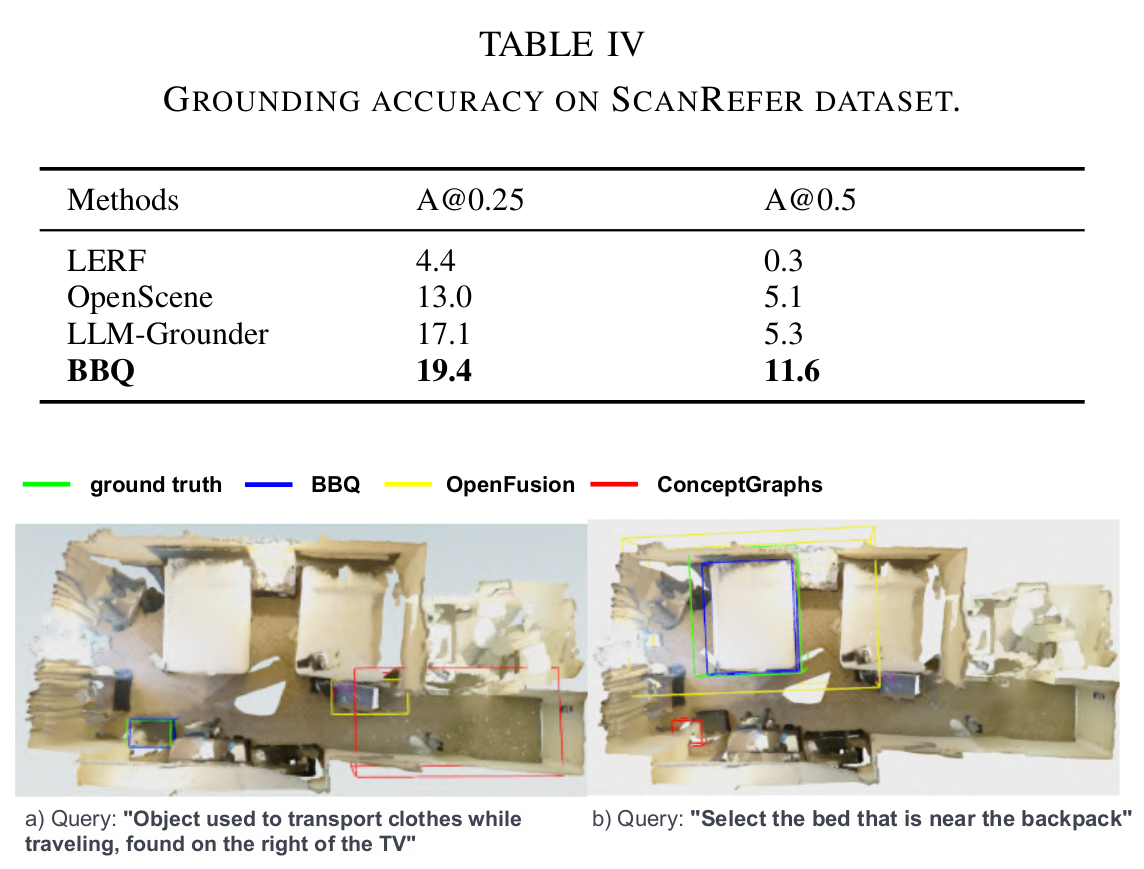
3D object grounding

BibTeX
@misc{linok2024barequeriesopenvocabularyobject,
title={Beyond Bare Queries: Open-Vocabulary Object Grounding with 3D Scene Graph},
author={Sergey Linok and Tatiana Zemskova and Svetlana Ladanova and Roman Titkov and Dmitry Yudin and Maxim Monastyrny and Aleksei Valenkov},
year={2024},
eprint={2406.07113},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2406.07113},
}
3D object grounding
BibTeX
@misc{linok2024barequeriesopenvocabularyobject,
title={Beyond Bare Queries: Open-Vocabulary Object Grounding with 3D Scene Graph},
author={Sergey Linok and Tatiana Zemskova and Svetlana Ladanova and Roman Titkov and Dmitry Yudin and Maxim Monastyrny and Aleksei Valenkov},
year={2024},
eprint={2406.07113},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2406.07113},
}
BibTeX
@misc{linok2024barequeriesopenvocabularyobject,
title={Beyond Bare Queries: Open-Vocabulary Object Grounding with 3D Scene Graph},
author={Sergey Linok and Tatiana Zemskova and Svetlana Ladanova and Roman Titkov and Dmitry Yudin and Maxim Monastyrny and Aleksei Valenkov},
year={2024},
eprint={2406.07113},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2406.07113},
}